Exploring the Enigma of John Mueller's Unusual Robots.txt
Delve into the mysterious world of John Mueller's robots.txt file, filled with peculiar directives and an astonishingly massive size that has captivated the curious minds of many
SEO Subreddit Post
Mueller's personal blog's robots.txt file caught the attention of many when a Reddit user suggested that it had been affected by Google's Helpful Content system and was removed from search results. However, the reality was not as extreme as initially thought, but it did raise some eyebrows.
The story of John Mueller's robots.txt began when a Redditor noticed that John Mueller's website had been deindexed, suggesting that it had violated Google's algorithm. However, upon closer inspection of the website's robots.txt file, it was clear that something unusual was happening.
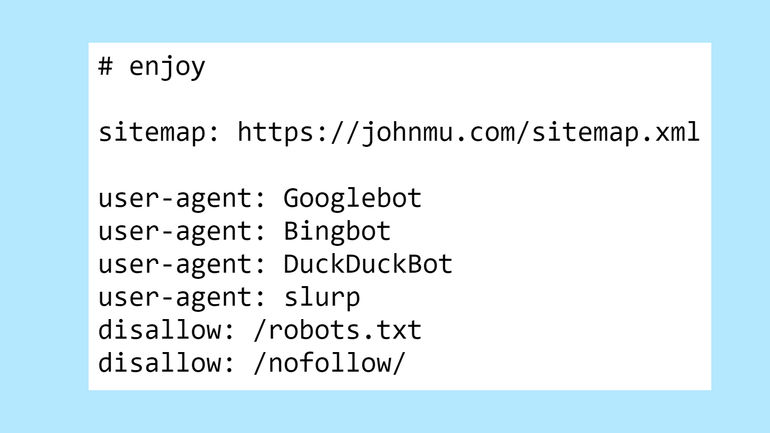
At the top of Mueller's robots.txt file, there is a hidden Easter egg for those who take a look.
The first bit that’s not seen every day is a disallow on the robots.txt. Who uses their robots.txt to tell Google to not crawl their robots.txt?
Now we know.
The Saga Of John Mueller’s Freaky Robots.txt
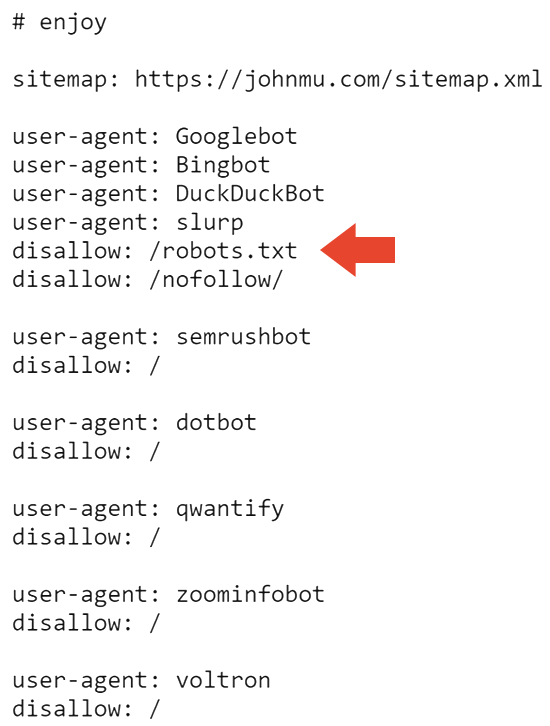
The next part of the robots.txt blocks all search engines from crawling the website and the robots.txt.
The Saga Of John Mueller’s Freaky Robots.txt
So that probably explains why the site is deindexed in Google. But it doesn’t explain why it’s still indexed by Bing.
After asking around, web developer and SEO expert Adam Humphreys shared his suggestion with me. He mentioned that Bingbot may not have visited Mueller's website yet due to its lack of activity. Adam messaged me his thoughts:
“User-agent: *
Disallow: /topsy/
Disallow: /crets/
Disallow: /hidden/file.html
In those examples the folders and that file in that folder wouldn’t be found.
He is saying to disallow the robots file which Bing ignores but Google listens to.
Bing would ignore improperly implemented robots because many don’t know how to do it. “
Adam also suggested that maybe Bing disregarded the robots.txt file altogether.
He explained it to me this way:
“Yes or it chooses to ignore a directive not to read an instructions file.
Improperly set up robots.txt instructions on Bing may be overlooked. This is because it serves as a guide for search engine crawlers.
The robots.txt file on Bing was last modified between July and November of 2023. It is possible that Bingbot has not yet accessed the updated version. This is because Microsoft's IndexNow web crawling system focuses on optimizing the crawling process.
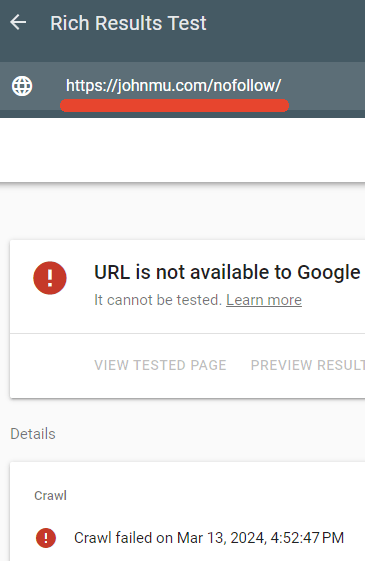
One directory that Mueller's robots.txt blocks is /nofollow/, which is a strange name for a folder. On this page, you will find very little content, just some site navigation and the word "Redirector."
I tested to see if the robots.txt was indeed blocking that page and it was.
Google’s Rich Results tester failed to crawl the /nofollow/ webpage.
The Saga Of John Mueller’s Freaky Robots.txt
John Mueller’s Explanation
Mueller appeared to be amused that so much attention was being paid to his robots.txt and he published an explanation on LinkedIn of what was going on.
He wrote:
"But, what's going on with the file? And why is your site no longer showing up on search engines?
One idea is that it could be due to the links to Google+. It's a possibility. As for the robots.txt file, it's set up the way I want it, and search engine crawlers should be able to handle it. At least, they should if they follow RFC9309."
Next he said that the nofollow on the robots.txt was simply to stop it from being indexed as an HTML file.
He explained:
No, adding "disallow: /robots.txt" to your robots.txt file does not make robots spin in circles or deindex your site. It simply prevents the robots.txt file itself from being crawled and indexed. This helps keep the content of your robots.txt file clean and organized.
I could also use the x-robots-tag HTTP header with noindex, but this way I have it in the robots.txt file too.”
Mueller also said this about the file size:
Through testing various robots.txt testing tools, my team and I have determined the ideal size. According to the RFC, a crawler should parse at least 500 kibibytes. If you allow infinite length, the system parsing the file will have to make a cut at some point.
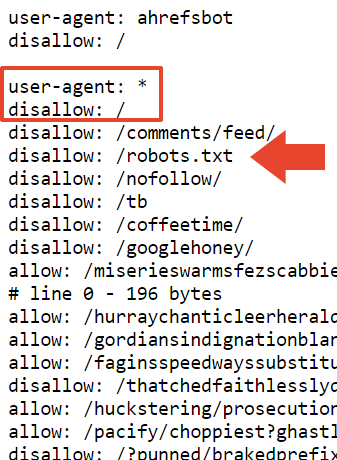
Additionally, he mentioned adding a disallow at the beginning of a section, hoping it would act as a "blanket disallow." However, the specific disallow he is referring to is unclear. His robots.txt file contains a total of 22,433 disallows.
I added a “disallow: /” at the beginning of that section. Hopefully, this will be recognized as a general disallow rule. There is a slight chance that the parser might stop abruptly at a line that includes “allow: /cheeseisbest”, causing a problem. In such cases, the parser will face a dilemma because the allow rule takes precedence over the disallow rule if both are present. However, this scenario seems highly unlikely.
And there it is. John Mueller’s weird robots.txt.
Robots.txt viewable here:
https://johnmu.com/**robots.txt**
Editor's P/S:
The Reddit post regarding John Mueller's unusual robots.txt file sparked a lively discussion within the SEO community. While initially perceived as an indication of Google's Helpful Content update, closer inspection revealed a more nuanced situation. Mueller's robots.txt file contained several peculiar directives, including a hidden Easter egg and a disallow for the robots.txt file itself. This raised questions about the impact on search engine crawling and indexing.
Mueller subsequently provided his own explanation, clarifying that the robots.txt file was intentionally configured in this manner to prevent the indexing of the robots.txt file as an HTML document. He also addressed the issue of file size, suggesting that crawlers should be able to parse files up to 500 kibibytes. The discussion highlights the importance of understanding the technical aspects of SEO and the complexities involved in configuring robots.txt files to effectively manage website crawling and indexing.












